Sumário
Introdução
Em problemas de regressão, modelos de aprendizado de máquina geralmente são capazes de apresentar predições pontuais com rigor; contudo, não raro negligenciam a quantificação da incerteza inerente a tais predições1 2. Essa limitação é particularmente crítica em aplicações reais, onde não apenas a precisão da previsão, mas também a confiabilidade e a quantificação da incerteza são cruciais para a tomada de decisões informadas3.
Neste cenário, modelos baseados em processos gaussianos (GP) destacam-se como uma abordagem robusta4. São capazes de fornecer não apenas predições pontuais, mas também distribuições de probabilidade completas para as predições5, permitindos capturar tanto a incerteza epistêmica quanto a incerteza aleatória. A incerteza epistêmica refere-se à incerteza no modelo devido à falta de dados ou conhecimento, podendo ser reduzida com mais observações, enquanto a incerteza aleatória é inerente ao processo de geração dos dados e não pode ser reduzida, representando o ruído natural do sistema6.
Processos gaussianos atribuem distribuição probabilística a funções, de modo que qualquer subconjunto finito de pontos amostrais obedece a uma distribuição gaussiana multivariada5. Tornam-se, assim, adequados para construir intervalos de predição, pois delimitam a faixa esperada para o valor real com uma probabilidade específica4.
Na prática, contudo, intervalos extraídos diretamente de um GP podem não entregar a cobertura nominal desejada7. É neste contexto que a predição conformal se apresenta como uma abordagem complementar8 9. Trata-se de uma técnica estatística que permite calibrar os intervalos de predição para garantir propriedades teóricas de cobertura, independentemente da distribuição subjacente dos dados ou da adequação do modelo10 11.
Uma configuração de modelo que integre GP e predição conformal torna-se uma abordagem promissora para a construção de intervalos que são simultaneamente informativos e confiáveis. Neste trabalho, investigamos essa configuração: implementamos o Processo Gaussiano aprimorado por rede neural (NE-GP, de Neural-Enhanced Gaussian Process) e o Processo Gaussiano Variacional Estocástico aprimorado por rede neural (NE-SVGP, de Neural-Enhanced Stochastic Variational Gaussian Process). Para cada um desses modelos, comparamos o desempenho dos intervalos de predição antes e após a aplicação do método conformal, em termos de cobertura e largura dos intervalos.
Metodologia
A implementação dos modelos propostos neste trabalho segue uma arquitetura híbrida que combina redes neurais com processos gaussianos, criando os modelos NE-GP e NE-SVGP. Esta abordagem utiliza as bibliotecas PyTorch e GPyTorch para implementar uma arquitetura de duas etapas: extração de características neurais seguida de modelagem probabilística gaussiana.
A arquitetura híbrida consiste em dois componentes principais integrados: um extrator de características baseado em perceptron multicamadas (MLP) que transforma os dados de entrada em representações de maior nível, e um GP que opera sobre essas características extraídas para fornecer predições de intervalos. O MLP é estruturado com três camadas totalmente conectadas: uma camada de entrada que recebe as características originais dos dados, duas camadas ocultas com 64 neurônios cada, aplicando funções de ativação ReLU e dropout de 0,1 para regularização, e uma camada de saída com 32 neurônios que produz as características refinadas.
O GP subsequente opera sobre essas características extraídas (\(\mathbf{z}\)), utilizando uma função de base radial para modelar as correlações no espaço de características transformado. A escolha do kernel Radial Basis Function deve-se à sua capacidade de capturar relações não-lineares suaves entre variáveis, sendo adequado para a maioria dos problemas de regressão. Outras opções como kernels periódicos ou Matérn poderiam ser usadas para capturar padrões específicos como sazonalidade ou diferentes graus de suavidade.
O treinamento conjunto otimiza simultaneamente os parâmetros do MLP (\(\mathbf{W}_i, \mathbf{b}_i\)) e os hiperparâmetros do GP (\(\boldsymbol{\theta}_{GP}\)) através de gradiente descendente
\[ \begin{aligned} \mathcal{L}(\mathbf{W}, \mathbf{b}, \boldsymbol{\theta}_{GP}) &= -\log p(\mathbf{y}\mid\text{MLP}(\mathbf{X}), \boldsymbol{\theta}_{GP}) \\ \boldsymbol{\phi}_{t+1} &= \boldsymbol{\phi}_t - \eta \nabla_{\boldsymbol{\phi}} \mathcal{L}(\boldsymbol{\phi}_t), \end{aligned} \]
onde \(\boldsymbol{\phi} = \{\mathbf{W}, \mathbf{b}, \boldsymbol{\theta}_{GP}\}\) representa todos os parâmetros treináveis do modelo híbrido.
Esta arquitetura híbrida une o poder das redes neurais na extração de características complexas com a precisão dos GPs na quantificação de incerteza.
Processos Gaussianos Exatos
Um GP é uma família de variáveis aleatórias tal que qualquer subconjunto finito segue uma distribuição gaussiana multivariada4 5. Tal propriedade garante exatidão à inferência bayesiana sem a necessidade de recorrer a aproximações numéricas — difere, por exemplo, de redes neurais bayesianas, que precisam de amostragem Monte Carlo ou métodos variacionais.
Formalmente, um GP é especificado por sua função de média \(m(\mathbf{x})\) e função de covariância \(k(\mathbf{x}, \mathbf{x'})\), onde
\[ \begin{aligned} m(\mathbf{x}) &= \mathbb{E}[f(\mathbf{x})] \\ k(\mathbf{x}, \mathbf{x'}) &= \mathbb{E}[(f(\mathbf{x}) - m(\mathbf{x}))(f(\mathbf{x'}) - m(\mathbf{x'}))] \end{aligned} \]
Assim, temos \(f(\mathbf{x}) \sim \mathcal{GP}(m, k)\) para indicar que a função \(f\) segue um GP com função de média \(m\) e função de covariância \(k\).
No problema de regressão, dada uma amostra de treinamento \(\mathcal{D} = {(\mathbf{x}_i, y_i)}_{i=1}^{n}\) e assumindo ruído gaussiano homoscedático \(y_i = f(\mathbf{x}_i) + \varepsilon_i\), onde \(\varepsilon_i \sim \mathcal{N}(0, \sigma^2)\), a posteriori para um novo ponto \(\mathbf{x}_*\) é gaussiana com parâmetros
\[ \begin{aligned} \mu(\mathbf{x}_*) &= \mathbf{k}_*^\top(\mathbf{K} + \sigma^2\mathbf{I})^{-1}\mathbf{y} \\ \sigma^2(\mathbf{x}_*) &= k(\mathbf{x}_*, \mathbf{x}_*) - \mathbf{k}_*^\top(\mathbf{K} + \sigma^2\mathbf{I})^{-1}\mathbf{k}_* \end{aligned} \]
onde \(\mathbf{K}\) é a matriz de covariância entre os pontos de treinamento e \(\mathbf{k}_*\) contém as covariâncias entre \(\mathbf{x}_*\) e cada \(\mathbf{x}_i\).
Neste trabalho, para obtermos funções-amostra suaves e isotrópicas, utilizamos a função de base radial para cálculo da covariância, definido como
\[ k(\mathbf{x}, \mathbf{x'}) = \sigma_f^2 \exp\left(-\frac{||\mathbf{x} - \mathbf{x'}||^2}{{{2l^2}}}\right) \]
onde \(\sigma_f^2\) é a variância do sinal e \(l\) é o comprimento de escala, que controla a suavidade da função. Estes hiperparâmetros são otimizados maximizando a log-verossimilhança marginal dos dados de treinamento. A log-verossimilhança marginal é obtida integrando sobre a função latente \(f\), resultando em
\[ \log p(\mathbf{y}|\mathbf{X}, \boldsymbol{\theta}) = -\frac{1}{2}\mathbf{y}^\top(\mathbf{K} + \sigma^2\mathbf{I})^{-1}\mathbf{y} - \frac{1}{2}\log|\mathbf{K} + \sigma^2\mathbf{I}| - \frac{n}{2}\log(2\pi) \]
onde \(\boldsymbol{\theta}\) são os hiperparâmetros do kernel. Esta otimização equilibra o ajuste aos dados com a complexidade do modelo.
Processo Gaussiano Variacional Estocástico
Uma limitação importante do GP exato é que ele exige complexidade computacional de \(\mathcal{O}(n^3)\) para treinamento e \(\mathcal{O}(n^2)\) para predição, onde \(n\) é o número de pontos de treinamento. Processo Gaussiano Variacional Estocástico (SVGP) reduz esses custos para \(\mathcal{O}(nm^{2}+m^{3})\) e \(\mathcal{O}(m^{2})\), respectivamente, ao introduzir um conjunto de \(m\) pontos-indutores em \(\mathbf Z={\mathbf z_{j}}_{j=1}^{m}\), com \(m\ll n\)12 13 14 15. Estes pontos-indutores são variáveis latentes que resumem as informações do conjunto de treinamento completo.
Neste modelo, aproximamos a distribuição a posteriori \(p(\mathbf{f} \mid \mathcal{D})\) por uma distribuição variacional \(q(\mathbf{f})\), isto é,
\[ q(\mathbf{f}, \mathbf{u}) = p(\mathbf{f} \mid \mathbf{u})q(\mathbf{u}), \]
onde \(\mathbf{f}\) são os valores da função nos pontos de treinamento, \(\mathbf{u}\) são os valores da função nos pontos-indutores, \(p(\mathbf{f} \mid \mathbf{u})\) é a distribuição condicional do GP, e \(q(\mathbf{u})\) é uma distribuição variacional gaussiana com parâmetros a serem otimizados.
A otimização é realizada minimizando a divergência Kullback-Leibler entre a distribuição variacional e a distribuição a posteriori verdadeira. A divergão entre duas distribuições contínuas de densidade \(p\) e \(q\) é definida como
\[ D_{\mathrm{KL}}(P \mid Q) = \int p(x),\ln!\biggl(\frac{p(x)}{q(x)}\biggr),\mathrm{d}x \]
Intuitivamente, \(D_{\mathrm{KL}}(P \mid Q)\) mede o excesso de informação exigido para representar amostras de \(P\) usando um código ótimo baseado em \(Q\) em vez de um código ótimo para \(P\) propriamente dito. Essa divergência é sempre não negativa e zera-se somente quando, para quase todo \(x\), tem-se \(p(x)=q(x)\).
A tarefa de minimizar a divergência equivale a maximizar um limite inferior da evidência (ELBO, Evidence Lower Bound).
A predição para um novo ponto \(\mathbf{x}_*\) é dada por
\[ \begin{aligned} q(f(\mathbf{x}_*)) &= \int p(f(\mathbf{x}_*) \mid \mathbf{u})q(\mathbf{u})d\mathbf{u} \\ &= \mathcal{N}(f(\mathbf{x}_*) \mid \mu_q(\mathbf{x}_*), \sigma_q^2(\mathbf{x}_*)), \end{aligned} \]
onde
\[ \begin{aligned} \mu_q(\mathbf{x}_*) &= \mathbf{k}_{*z}\mathbf{K}_{zz}^{-1}\boldsymbol{\mu}_u \\ \sigma_q^2(\mathbf{x}_*) &= k(\mathbf{x}_*, \mathbf{x}_*) - \mathbf{k}_{*z}\mathbf{K}_{zz}^{-1}(\mathbf{K}_{zz} - \mathbf{S}_u)\mathbf{K}_{zz}^{-1}\mathbf{k}_{z*} \end{aligned} \]
sendo \(\mathbf{k}_{*z}\) o vetor de covariâncias entre \(\mathbf{x}_*\) e os pontos-indutores, \(\mathbf{K}_{zz}\) a matriz de covariância entre os pontos-indutores, e \(\boldsymbol{\mu}_u\) e \(\mathbf{S}_u\) os parâmetros da distribuição variacional \(q(\mathbf{u}) = \mathcal{N}(\boldsymbol{\mu}_u, \mathbf{S}_u)\).
Neste trabalho, inspirados nos gargalos de underfitting e instabilidade numérica16, utilizamos extensões ao SVGP padrão, tais como seleção adaptativa dos pontos-indutores com base na distribuição dos dados, otimização conjunta dos pontos-indutores e dos hiperparâmetros do kernel, uso de mini-batches durante o treinamento para melhorar a eficiência computacional, e implementação de técnicas de estabilidade numérica, como a decomposição de Cholesky17 — ou seja, fatoração de uma matriz simétrica e definida positiva \(A\) em \(A = LL^\top\), onde \(L\) é matriz triangular inferior com elementos positivos na diagonal — para o cálculo de inversas de matrizes.
Essas melhorias permitem que o SVGP retenha a interpretação probabilística do GP clássico, escale para conjuntos de dados com centenas de milhares de amostras e produza intervalos de predição que combinam validez estatística e largura competitiva.
Predição Conformal
Dada a natureza probabilística dos modelos baseados em GP, os intervalos de predição podem ser derivados diretamente da distribuição a posteriori. Para um nível de confiança \(1-\alpha\), o intervalo de predição para um novo ponto \(\mathbf{x}_*\) é:
\[ PI_{1-\alpha}(\mathbf{x}_*) = [\mu(\mathbf{x}_*) - z_{1-\alpha/2} \cdot \sigma(\mathbf{x}_*), \mu(\mathbf{x}_*) + z_{1-\alpha/2} \cdot \sigma(\mathbf{x}_*)] \]
onde \(z_{1-\alpha/2}\) é o quantil \(1-\alpha/2\) da distribuição normal padrão.
Este intervalo de predição tem uma interpretação bayesiana: assumindo que o modelo e seus hiperparâmetros estão corretos, o intervalo contém o valor verdadeiro com probabilidade \(1-\alpha\). No entanto, na prática, essas suposições podem não ser válidas, levando a intervalos que não atingem a cobertura nominal desejada. A predição conformal9 10 é uma abordagem estatística que permite calibrar os intervalos de predição para garantir propriedades teóricas de cobertura, independentemente da distribuição subjacente dos dados ou da adequação do modelo. A ideia central é usar um conjunto de calibração para determinar o quanto os intervalos de predição devem ser contraídos para atingir a cobertura desejada.
Neste trabalho, implementamos uma variante da predição conformal conhecida como predição conformal indutiva18, que utiliza um conjunto de validação separado para calibração. Além disso, fazemos uso de um escore de não-conformidade natural, dado por
\[ s_i = \max\{y_i - l(\mathbf{x}_i), u(\mathbf{x}_i) - y_i, 0\} \]
e escolhido por sua simplicidade e interpretabilidade: trata-se do erro absoluto normalizado entre a predição e o valor verdadeiro; mede o quanto o valor verdadeiro está fora do intervalo de predição original.
Uma propriedade teórica importante da predição conformal é que, sob a suposição de permutabilidade dos dados, os intervalos de predição conformal garantem uma cobertura marginal de pelo menos \(1-\alpha\) no conjunto de teste7. Isso significa que, em média, pelo menos uma fração \(1-\alpha\) dos intervalos conterá os valores verdadeiros, independentemente da adequação do modelo ou da distribuição dos dados.
Execução de Testes
Avaliamos os modelos em três conjuntos de dados públicos amplamente utilizados em problemas de regressão: Combined Cycle Power Plant19 (CCPP), que contém informações de uma usina de ciclo combinado, com o objetivo de prever a potência elétrica líquida; Concrete Compressive Strength20 (Concrete), que contém valores para diferentes misturas de concreto, com o objetivo de prever a resistência à compressão; e Condition Based Maintenance of Naval Propulsion Plants21 (Naval), que contém medições de uma planta de propulsão naval, com o objetivo de prever o coeficiente de decaimento do estado do compressor.
| Conjuntos | Dimensionalidade | Amostras | Assimetria de \(y\) | Curtose de \(y\) |
|---|---|---|---|---|
| CCPP | 5 | 9.568 | 0,31 | 1,95 |
| Concrete | 9 | 1.030 | 0,42 | 2,69 |
| Naval | 18 | 11.934 | 0,00 | 1,80 |
Estes conjuntos de dados foram escolhidos por representarem uma variedade de domínios e características, permitindo uma avaliação abrangente dos modelos em diferentes contextos. Para avaliar o desempenho dos intervalos de predição, utilizamos como métricas a cobertura, a largura média dos intervalos de predição (MPIW) e o desempenho.
Cobertura é a fração de pontos de teste para os quais o valor verdadeiro está contido no intervalo de predição. Formalmente, para um conjunto de teste com \(n\) pontos, a cobertura é
\[ \text{Cobertura} = \frac{1}{n}\sum_{i=1}^{n}\mathbf{1}\{y_i \in PI(\mathbf{x}_i)\} \]
onde \(\mathbf{1}\{\cdot\}\) é a função indicadora. Um bom intervalo de predição deve ter uma cobertura próxima ao nível de confiança nominal (\(1-\alpha\)).
MPIW, a média da largura dos intervalos de predição, é obtida por meio de
\[ \text{MPIW} = \frac{1}{n}\sum_{i=1}^{n}(u(\mathbf{x}_i) - l(\mathbf{x}_i)) \]
onde \(l(\mathbf{x}_i)\) e \(u(\mathbf{x}_i)\) são os limites inferior e superior do intervalo de predição para \(\mathbf{x}_i\). Um bom intervalo de predição deve ser o mais estreito possível, condicionado a atingir a cobertura desejada.
Para avaliar a precisão das predições pontuais, utilizamos o coeficiente de determinação \(R^2\), que mede a proporção da variância na variável dependente que é previsível a partir das variáveis independentes. Valores mais altos de \(R^2\) indicam melhor desempenho preditivo.
Além dessas métricas principais, também calculamos métricas secundárias para uma análise mais detalhada, tais como a diferença entre a cobertura conformada e a cobertura bruta, a diferença entre a largura média do intervalo conformado e a largura média do intervalo bruto, a fração de pontos de teste para os quais o valor verdadeiro está abaixo do limite inferior ou acima do limite superior do intervalo de predição, a razão entre a largura média do intervalo conformado e a largura média do intervalo bruto, e a razão entre a diferença de cobertura e a diferença de largura, que mede a eficiência da calibração conformal.
Para garantir a robustez dos resultados, cada conjunto de dados foi treinado utilizando cinco sementes distintas por até 200 épocas, com a possibilidade de parada antecipada no caso de a função de perda não apresentar melhoria por 10 épocas consecutivas, utilizando um delta mínimo de \(1 \times 10^{-6}\) para considerar uma melhoria significativa.
Resultados
Os resultados mostram padrões interessantes no comportamento dos modelos. Em primeiro lugar, observamos que os intervalos de predição brutos geralmente têm coberturas significativamente mais altas que o nível nominal de 90%.
| Modelo | Conjuntos | Cobertura (%) | MPIW | R² | ||
|---|---|---|---|---|---|---|
| Bruto | Conformal | Bruto | Conformal | |||
| NE-GP | CCPP | 99,89 | 90,13 | 2,64 | 0,76 | 0,941 |
| Concrete | 99,03 | 91,55 | 2,72 | 1,47 | 0,796 | |
| Naval | 100,00 | 89,38 | 2,66 | 0,83 | 0,933 | |
| NE-SVGP | CCPP | 90,93 | 90,13 | 0,76 | 0,75 | 0,945 |
| Concrete | 98,83 | 90,87 | 2,14 | 1,18 | 0,877 | |
| Naval | 96,65 | 90,26 | 0,52 | 0,39 | 0,984 | |
A tabela mostra que, no caso do NE-GP, as coberturas da predição bruta variam de 99,03% a 100,00%, enquanto para o NE-SVGP variam de 90,93% a 98,83%. Isso indica que os intervalos com predição bruta são, de maneira frequente, excessivamente conservadores, resultando em uma cobertura maior que a necessária.
Após a aplicação do método conformal, as coberturas são consistentemente ajustadas para valores próximos a 90%, o que é o nível de cobertura nominal desejado. Esse resultado confirma a eficácia da predição conformal em calibrar os intervalos de predição para atingir a cobertura desejada, independentemente do modelo ou do conjunto de dados.
Em relação à largura dos intervalos, observamos que, na maioria dos casos, a predição conformal resultou em intervalos mais estreitos. Isso é uma consequência direta da redução da cobertura para o nível nominal de 90%. É importante notar que, idealmente, desejamos intervalos de predição que sejam o mais estreitos possível, condicionado a atingir a cobertura desejada. Quanto ao desempenho, vemos que o NE-SVGP supera significativamente o NE-GP nos conjuntos de dados Naval (0,984 contra 0,933) e Concrete (0,877 contra 0,796), além de apresentar desempenho ligeiramente superior no conjunto CCPP (0,945 contra 0,941).
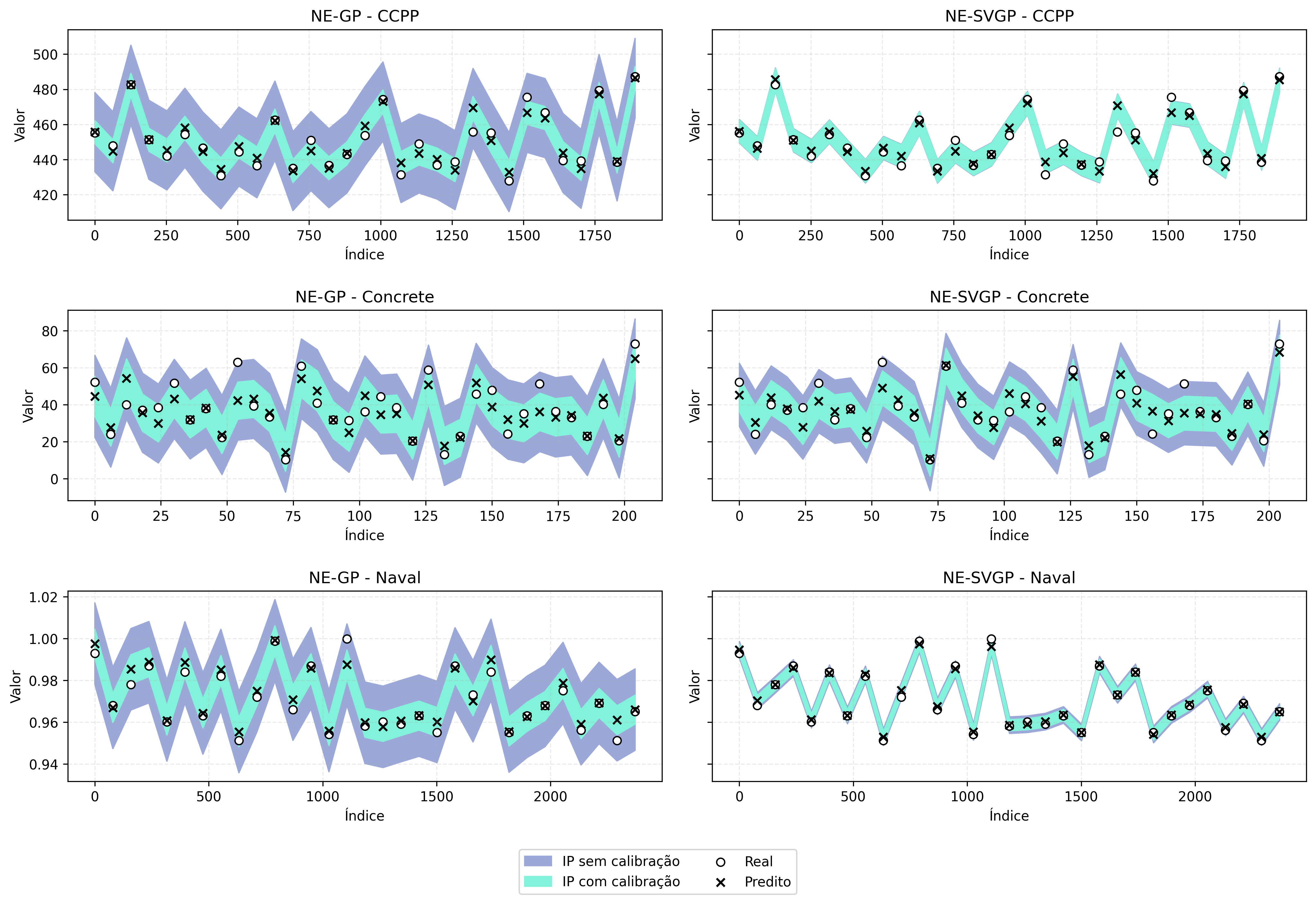
A figura, com resultados de execuções na semente 42, ilustra o trade-off entre cobertura e largura dos intervalos. Com NE-GP, em todos os conjuntos de dados, a calibração conformal reduz a cobertura para aproximadamente 90%, enquanto também reduz a largura dos intervalos. O efeito é particularmente pronunciado no conjunto CCPP, onde a largura média é reduzida de 2,64 para 0,76, uma redução de 71,2%, enquanto a cobertura passa de 99,89% para 90,13%.
De forma análoga, para NE-SVGP, observamos um padrão semelhante, mas com algumas diferenças notáveis. Em particular, os intervalos brutos já são geralmente mais estreitos em comparação ao modelo NE-GP, e a redução proporcional na largura após a calibração conformal é menor. Por exemplo, no conjunto CCPP, a largura média é reduzida de 0,76 para 0,75, uma redução de apenas 1,3%, enquanto a cobertura passa de 90,93% para 90,13%.
Além dessas métricas, os resultados também podem ser avaliados pela porcentagem de erros que, após a predição conformal, se distribuem entre os limites inferior e superior; pela razão entre a largura média do intervalo conformado e a largura média do intervalo bruto, em que valores menores indicam uma redução mais significativa após a aplicação do método conformal; pela redução do excesso de cobertura, que mede a eficiência da predição conformal ao quantificar o ganho obtido por unidade de redução na largura; e pelo erro de calibração, isto é, a diferença absoluta entre a cobertura alcançada e o nível nominal de 90%.
| Modelo | Conjunto | Erros (%) | Razão entre Larguras | Redução do Excesso de Cobertura | Erro de Calibração | ||
|---|---|---|---|---|---|---|---|
| Inferior | Superior | Bruta | Conformal | ||||
| NE-GP | CCPP | 4,22 | 5,65 | 0,289 | 0,052 | 0,099 | 0,002 |
| Concrete | 4,27 | 4,17 | 0,541 | 0,060 | 0,090 | 0,020 | |
| Naval | 7,63 | 2,98 | 0,310 | 0,058 | 0,100 | 0,008 | |
| NE-SVGP | CCPP | 4,25 | 5,62 | 0,976 | 0,339 | 0,009 | 0,005 |
| Concrete | 3,69 | 5,44 | 0,551 | 0,083 | 0,088 | 0,020 | |
| Naval | 8,35 | 1,38 | 0,750 | 0,553 | 0,066 | 0,006 | |
A tabela revela padrões interessantes na distribuição de erros e na eficácia da calibração conformal. Para o NE-GP, observamos uma distribuição relativamente equilibrada de erros entre os limites inferior e superior nos conjuntos CCPP (4,22% inferior vs. 5,65% superior) e Concrete (4,27% inferior vs. 4,17% superior), enquanto o conjunto Naval apresenta uma assimetria notável com 7,63% de erros no limite inferior contra apenas 2,98% no superior.
A razão entre larguras confirma a eficácia da calibração conformal em reduzir significativamente a largura dos intervalos. Para o NE-GP, observamos reduções substanciais: CCPP com razão de 0,289 (redução de 71,1%), Concrete com 0,541 (redução de 45,9%) e Naval com 0,310 (redução de 69,0%). O NE-SVGP apresenta comportamento distinto, com uma redução mais modesta no CCPP (razão de 0,976, apenas 2,4%) mas reduções significativas no Concrete (0,551, redução de 44,9%) e Naval (0,750, redução de 25,0%).
O erro de calibração demonstra a superioridade da predição conformal. Para o NE-GP, os erros de calibração brutos variam de 0,090 a 0,100, sendo consistentemente reduzidos para valores próximos a zero após a calibração conformal (0,002 a 0,020). O NE-SVGP já apresenta erros de calibração brutos menores (0,009 a 0,088), mas ainda se beneficia da calibração conformal, alcançando erros finais de 0,005 a 0,020.
Conclusão
Este trabalho investigou em profundidade a integração de processos gaussianos potencializados por redes neurais com a predição conformal como estratégia de calibração de intervalos de predição. Os resultados obtidos em três conjuntos de dados de natureza diversa evidenciam que a conformação fornece ganhos substanciais tanto em confiabilidade estatística quanto em eficiência informacional.
Antes da calibração, os intervalos brutos exibiam coberturas muito superiores ao nível nominal de 90%, chegando a 100% no NE-GP para o conjunto Naval e a 99,89% no CCPP. Esse excesso de cobertura, embora pareça desejável à primeira vista, revela intervalos excessivamente largos e, portanto, pouco úteis na prática. A aplicação da predição conformal ajustou sistematicamente a cobertura para valores muito próximos a 90%, confirmando, na prática, as garantias teóricas do método: a cobertura marginal converge ao nível definido independentemente do ajuste do modelo ou da distribuição dos dados.
A eficiência desse ajuste refletiu-se diretamente na largura média dos intervalos. No cenário mais expressivo, o CCPP com NE-GP sofreu uma redução de 71,2% na largura após a calibração, de 2,64 para 0,76 unidades, sem comprometer a taxa de acerto exigida. Mesmo no NE-SVGP, onde as larguras iniciais já eram menores devido ao caráter variacional esparso do modelo, observou-se uma diminuição adicional que, embora mais discreta em CCPP (1,3%), alcançou valores consideráveis em Concrete (44,9%) e Naval (25%).
Esses achados ressaltam um ponto central: a calibração conformal não apenas corrige a cobertura, mas também tende a remover redundância estatística, comprimindo os intervalos até o limite necessário para preservar o nível de confiança. Em outras palavras, ela transforma incerteza superabundante em informação útil.
O contraste entre os dois modelos avaliados fornece observações adicionais. O NE-SVGP, graças ao emprego de pontos-indutores e otimização variacional, obteve desempenho preditivo superior em termos de \(R^2\), chegando a 0,984 no conjunto Naval, e produziu intervalos brutos mais estreitos do que o NE-GP. Ainda assim, não dispensou a calibragem: pequenas violações de cobertura ou assimetrias na distribuição de erros foram corrigidas após a conformação.
Para o NE-GP, a dependência da calibração foi ainda mais explícita, dada a tendência do modelo a superestimar incerteza em domínios com alto ruído ou desbalanceamento de características. Portanto, a predição conformal mostrou-se um complemento robusto a ambos os paradigmas: age como uma "segunda linha de defesa" contra defeitos de especificação do modelo e falhas nos pressupostos de ruído homoscedástico ou distribuição independente e identicamente distribuída.
Apesar desses êxitos, algumas limitações merecem destaque. Em primeiro lugar, a extensão natural deste trabalho passa pela incorporação explícita de heteroscedasticidade, seja por meio de GPs variacionais locais, seja por modelos híbridos que aprendam a variância condicional da saída. Em segundo lugar, ainda que o SVGP escale melhor que o GP exato, conjuntos com milhões de amostras podem demandar particionamento hierárquico que preservem as garantias da predição conformal.
Além disso, a investigação restringiu-se a tarefas de regressão. Como a estrutura teórica do conformal é agnóstica à função de perda, há terreno fértil para explorar classificações ordinais, detecção de anomalias e previsão intervalar em séries temporais, onde pressupostos de permutabilidade precisam ser revisitados.
Referências
GAL, Y. Uncertainty in deep learning. Tese (Doutorado) — University of Cambridge, Cambridge, 2016. ↩
KULESHOV, V.; FENNER, N.; ERMON, S. Accurate uncertainties for deep learning using calibrated regression. In: International Conference on Machine Learning, 35., 2018, p. 2796–2804. ↩
HÜLLERMEIER, E.; WAEGEMAN, W. Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods. Machine Learning, v. 110, n. 3, p. 457–506, 2021. ↩
RASMUSSEN, C. E.; WILLIAMS, C. K. I. Gaussian processes for machine learning. Cambridge, MA: MIT Press, 2005. ↩ ↩2 ↩3
MURPHY, K. P. Machine learning: a probabilistic perspective. Cambridge, MA: MIT Press, 2012. ↩ ↩2 ↩3
KENDALL, A.; GAL, Y. What uncertainties do we need in Bayesian deep learning for computer vision? In: Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS'17), Long Beach, CA, EUA, p. 5580–5590, 2017. ↩
ANGELOPOULOS, A. N.; BATES, S. A gentle introduction to conformal prediction and distribution-free uncertainty quantification. arXiv preprint arXiv:2107.07511, 2022. ↩ ↩2
BALASUBRAMANIAN, V.; HO, S.-S.; VOVK, V. Conformal prediction for reliable machine learning: theory, adaptations and applications. 1. ed. San Francisco: Morgan Kaufmann Publishers Inc., 2014. ↩
VOVK, V.; GAMMERMAN, A.; SHAFER, G. Algorithmic learning in a random world. New York, NY: Springer, 2005. ↩ ↩2
SHAFER, G.; VOVK, V. A tutorial on conformal prediction. The Journal of Machine Learning Research, v. 9, p. 371–421, 2008. ↩ ↩2
LEI, J.; G'S ELL, M.; RINALDO, A.; TIBSHIRANI, R. J.; WASSERMAN, L. Distribution-free predictive inference for regression. Journal of the American Statistical Association, v. 113, n. 523, p. 1094–1111, 2018. ↩
QUINONERO-CANDELA, J.; RASMUSSEN, C. E. A unifying view of sparse approximate Gaussian process regression. Journal of Machine Learning Research, v. 6, n. 65, p. 1939–1959, 2005. ↩
SNELSON, E.; GHAMRAMANI, Z. Sparse Gaussian processes using pseudo-inputs. In: Advances in Neural Information Processing Systems, v. 18, p. 1257–1264, 2005. MIT Press. ↩
TITSIAS, M. Variational learning of inducing variables in sparse Gaussian processes. In: Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, 5., Clearwater, FL: PMLR, p. 567–574, 2009. ↩
HENSMAN, J.; FUSI, N.; LAWRENCE, N. D. Gaussian processes for big data. In: Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence, Bellevue, WA; Arlington, VA: AUAI Press, p. 282–290, 2013. ↩
DEWOLF, N.; DE BAETS, B.; WAEGEMAN, W. Valid prediction intervals for regression problems. Artificial Intelligence Review, v. 56, n. 1, p. 577–613, 2023. ↩
GOLUB, G. H.; VAN LOAN, C. F. Matrix computations. 4. ed. Baltimore, MD: Johns Hopkins University Press, 2013. ↩
PAPADOPOULOS, H.; PROEDROU, K.; VOVK, V.; GAMMERMAN, A. Inductive confidence machines for regression. In: Machine Learning: ECML 2002, Berlin; Heidelberg: Springer Berlin Heidelberg, p. 345–356, 2002. ↩
TFEKCI, P.; KAYA, H. Combined cycle power plant. UCI Machine Learning Repository, 2014. ↩
YEH, I.-C. Concrete compressive strength. UCI Machine Learning Repository, 1998. ↩
CORADDU, A.; ONETO, L.; GHIO, A.; SAVIO, S.; ANGIUTA, D.; FIGARI, M. Condition based maintenance of naval propulsion plants. UCI Machine Learning Repository, 2014. ↩